Many customers would like to view their cluster metrics alongside existing performance data using Prometheus/Grafana
Currently Nutanix does not provide a native exporter for Prometheus to use as a datasource. However we can use the prometheus push-gateway and a simple script which pulls from the native APIs to get data into prometheus. From there we can use Grafana or anything that can connect to Prometheus.
The goal is to be able to view cluster metrics alongside other Grafana dashboards. For example show the current Read/Write IOPS that the cluster is delivering on a per container basis. I’m hard-coding IPs and username/passwords in the script which obviously is not production grade, so don’t do that.
The topology (layout) that AHV presents virtual Sockets/CPU to the guest operating system will usually be different than the physical topology. This is expected because we typically present a subset of all cores to the guest VMs.
Usually it is the total number of vCPU given to the VM that matters, not the specific topology, but in the case of SQLserver running an analytical workload (a TPC-H like workload from HammerDB) the topology passed to the VM does make a difference. Between 10% and 20% when measured by the total runtime.
[I think that the reason we see a difference here is that (a) the analytical workloads use hardly any storage bandwidth (I sized the database to fit in memory) and (b) there is probably a lot of cross-talk between the cores/memory as the DB engine issues parallel queries.]
At any rate we see that passing 20 cores as “20 sockets of 1 core” beats the performance of “1 socket with 20 cores” by a wide margin. The physical topology is two sockets of 20 cores on each socket. Thankfully the better performing option is the default.
CPU Topology may make a difference for SQL server running analytical workloads.Continue reading →
I was recently asked to investigate why Nutanix storage was not as fast as a competing solution in a PoC environment. When I looked at the output from diskspd, the data didn’t quite make sense.
In a recent experiment using Amazon RDS instance and a VM running in an on-prem Nutanix cluster, both using Skylake class processors with similar clock speeds and vCPU count. The SQLServer database on Nutanix delivered almost 2X the transaction rate as the same workload running on Amazon RDS.
It turns out that migrating an existing SQLServer VM to RDS using the same vCPU count as on-prem may yield only half the expected performance for CPU heavy database workloads. The root cause is how Amazon thinks about vCPU compared to on-prem.
AOS 6.1 greatly improved database performance on Nutanix especially when the guest VM uses just a single disk for all the database files. The underlying change is known as vdisk sharding. Basically it allows the Nutanix CVM to scale up the number of threads used to service a single virtual disk under heavy load.
Once connected to the appliance we can use postgres and pgbench to generate simplistic database workload.
[1] Do this on a Linux box somewhere. For some reason the conversion failed using my qemu utilities installed via brew. Importing OVAs direct into AHV should be available in the future.
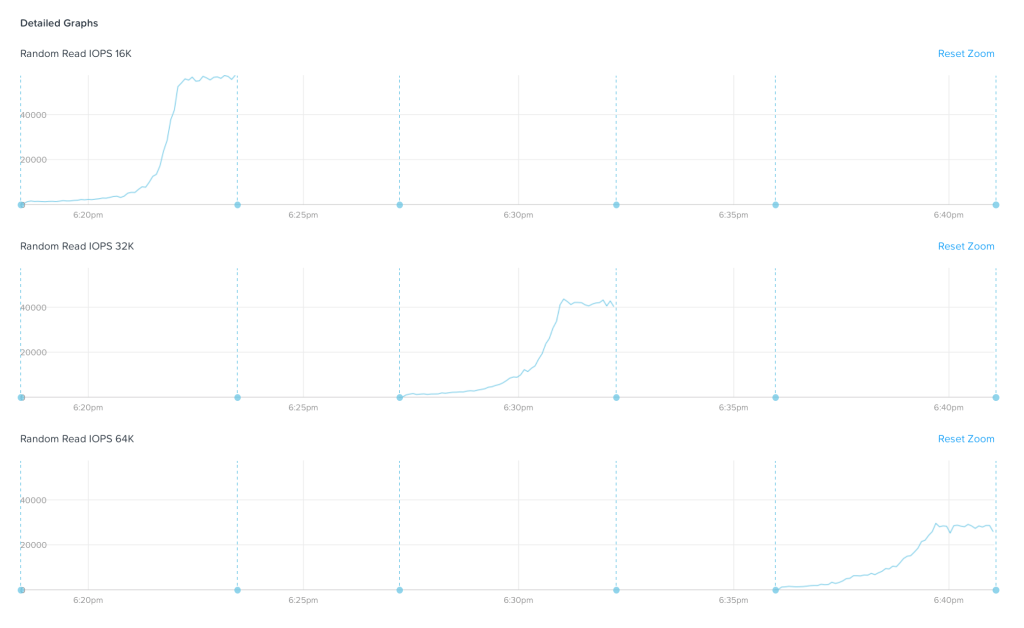
Specifically a customer wanted to see how performance changes (and how quickly) as data moves from HDD to SSD automatically as data is accessed. The access pattern is 100% random across the entire disk.
In a hybrid Flash/HDD system – “cold” data (i.e. data that has not been accessed for a long time) is moved from SSD to HDD when the SSD capacity is exhausted. At some point in the future – that same data may become “hot” again, and so we want to make sure that the “newly hot” data is quickly moved back to the SSD tier. The duration of the above chart is around 5 minutes – and we see that by, around the 3 minute mark the entire dataset is resident on the SSD tier.
This X-ray test uses a couple of neat tricks to demonstrate ILM behavior.
Edit container preferences to send sequential data immediately to HDD
Overwriting data with NUL/Zero bytes frees the underlying data on Nutanix filesystem
To demonstrate ILM from HDD to SSD (ad ultimately into the DRAM cache on the CVM) we first have to ensure that we have data on the HDD in the first place. By default Nutanix OS will always try to write new data to SSD. To circumvent that behavior we can edit the container preferences. We use the fact that the “prefill” will be a sequential workload, while the measured workload will be a random workload. To make the change, use “ncli” to change the ” Sequential I/O Pri Order” to be HDD only.
In my case I happened to call my container “xray” since I didn’t want to change the default container. Now, when X-Ray executes the prefill stage, the data will land on HDD. As a second requirement, we want to see what happens when IO with different size blocks are issued so that we can get a chart similar to this: To achieve the desired behavior, we need to make sure that, at the beginning of each test, the data, again resides on HDD. The problem is that the data is up-migrated during the test. To do this we do an initial overwrite of the entire disk with “NULL” bytes using a parameter in fio “zero_buffers”. This causes the data to be freed on the Nutanix filesystem. Then we issue a normal profile with random data. Once the data is freed, then we know that the new initial writes will go to HDD – because we edited the container to do so. The overall test pattern looks like this
Create and clone VMs
Prefill with random data (Data will reside on HDD due to container edit)
Read disk with 16KB block size
Zero out the disks – to remove/free the up-migrated data
What happens when power is lost to all nodes of a HCI Cluster?
Ever wondered what happens when all power is simultaneously lost on a HCI cluster? One of the core principles of cloud design is that components are expected to fail, but the cluster as a whole should stay “up”. We wanted to see what happens when all components fail at once, so we designed an X-Ray test to do exactly that.
We start an OLTP workload on every node in the cluster, then X-Ray connects to the IPMI port on each node, and powers off all the hosts while the cluster is under load. In particular, the cluster is under read/write load (we need write workload, because we want to force the cluster to recover in-flight writes).
After power-off, we wait 10 seconds for everything to spin down, then immediately re-apply the power by connecting to the IPMI ports.
The nodes power up, and immediately start their POST (Power On Self Test) and boot the hypervisor. The CVM will auto-start, discover the available nodes and form the cluster.
X-Ray polls the cluster manager (either Prism or vCenter) to determine that the cluster is “up” and then restarts the OLTP workload.
Our testing showed that our Nutanix cluster completed POST, and was ready to restart work in around 10 minutes. Moreover, the time to achieve the recovery had very little variability. The chart below shows three separate runs on the same cluster.
This is the YAML file which defines the workload. The full specification is on github. The key part of the YAML is the nodes.PowerOff which connects to the IMPI ports of each node and vm_group.WaitForPowerOn which connects to either Nutanix Prism or vmware vCenter and determines that the cluster is formed, and ready to accept new work.
We have started seeing misaligned partitions on Linux guests runnning certain HDFS distributions. How these partitions became mis-aligned is a bit of a mystery, because the only way I know how to do this on Linux is to create a partition using old DOS format like this (using -c=dos and -u=cylinders) Continue reading →
buffer_compress_percentage does what you’d expect and specifies how compressible the data is
refill_buffers Is required to make the above compress percentage do what you’d expect in the large. IOW, I want the entire file to be compressible by the buffer_compress_percentage amount
buffer_pattern This is a big one. Without setting this pattern, fio will use Null bytes to achieve compressibility, and Nutanix like many other storage vendors will suppress runs of Zero’s and so the data reduction will mostly be from zero suppression rather than from compression.
Much of this is well explained in the README for latest version of fio.
Also NOTE Older versions of fio do not support many of the fancy data creation flags, but will not alert you to the fact that fio is ignoring them. I spent quite a bit of time wondering why my data was not compressed, until I downloaded and compiled the latest fio.
The question of why Nutanix uses SATA drive comes up sometimes, especially from customers who have experienced very poor performance using SATA on traditional arrays.
I can understand this anxiety. In my time at NetApp we exclusively used SAS or FC-AL drives in performance test work. At the time there was a huge difference in performance between SCSI and SATA. Even a few short years ago, FC typically spun at 15K RPM whereas SATA was stuck at about a 5K RPM, so experiencing 3X the rotational delay.
These days SAS and SATA are both available in 7200 RPM configurations, and these are the type we use in standard Nutanix nodes. In fact the SATA drives that we use are marketed by Seagate as “Nearline SAS” or NL-SAS. Mainly to differentiate them from the consumer grade SATA drives that are found in cheap laptops. There are hundreds of SAS Vs SATA articles on the web, so I won’t go over the theoretical/historical arguments.
SATA in Hybrid/Tiered Storage
In a Nutanix cluster the “heavy lifting” of IO is mainly done by the SSD’s – leaving the SATA drives to service the few remaining IO’s that miss the SSD tier. Under moderate load, the SATA spindles do pretty well, and since the SATA $/GB is only 60% of SAS. SATA seems like a good choice for mostly-cold data.
Let’s Experiment.
From a performance perspective, I decided to run a few experiments to see just how well SATA performs. In the test, the SATA drives are Nutanix standard drives “ST91000640NS” (Seagate, priced around $150). The comparable SAS drives are the same form-factor (2.5 Inch) “AL13SEB900” (Toshiba, priced at about $250 USD). These drives spin at 10K RPM. Both drives hold around 1TB.
There are three experiments per drive type to reveal the impact of seek-times. This is achieved using the “filesize” parameter of fio – which determines the LBA range to read. One thing to note, is that I use a queue-depth of one. Therefore IOPs can be calculated as simply 1/Response-Time (converted to seconds).
Somewhat intuitively as the working-set (seek) gets larger, the difference between “Real SAS” and “NL-SAS/SATA” gets wider. This is intuitive because with a 1GB working-set, the seek-time is close to zero, and so only the rotational delay (based on RPM) is a factor. In fact the difference in response time is the same as the difference in rotational speed (1:1.3).
Also (just for fun) I used the “random_distribution=zipf” function in fio to test the response time when reading across the entire range of the disk – but with a “hotspot” (zipf) rather than a uniform random read – which is pretty unrealistic.
In the “realistic” case – reading across the entire disk on the SATA drives shipped with Nutanix nodes is capable of 8.5 ms response time at 125 IOPS per spindle.
Conclusion
The performance difference between SAS and SATA is often over-stated. At moderate loads SATA performs well enough for most use-cases. Even when delivering fully random IO over the entirety of the disk – SATA can deliver 8K in less than 15ms. Using a more realistic (not 100% random) access pattern the response time is < 10ms.
For a properly sized Nutanix implementation, the intent is to service most IO from Flash. It’s OK to generate some work on HDD from time-to-time even on SATA.
Although the paper uses examples of both a webserver and a gnutella client, the philosophies are relevant to a large scale distributed filesystem. In the case of NDFS we are serving disk blocks to clients who happen to be virtual machines. One trade-off that is true in both cases is that scalability is traded for low latency in the single-stream case. However at load, the response time is generally better than a system that is designed to low-latency, and then attempted to scale-up to achive high throughput.
At Nutanix we often talk about web-scale architectures, and this paper gives a pretty solid idea of what that might mean in concrete terms.
FWIW., according to google scholar, the paper has been cited 937 times, including Cassandra which is how we store filesystem meta-data in a distributed fashion.