How to use some of Linux’s standard tools and how different types of memory usage shows up.
Examples of using malloc and writing to memory with three use-cases for a simple process
- No memory allocation at all no_malloc.c
- A call to
malloc()but memory is not written to malloc only.c - A call to
malloc()and then memory is written to the allocated space malloc and write.c
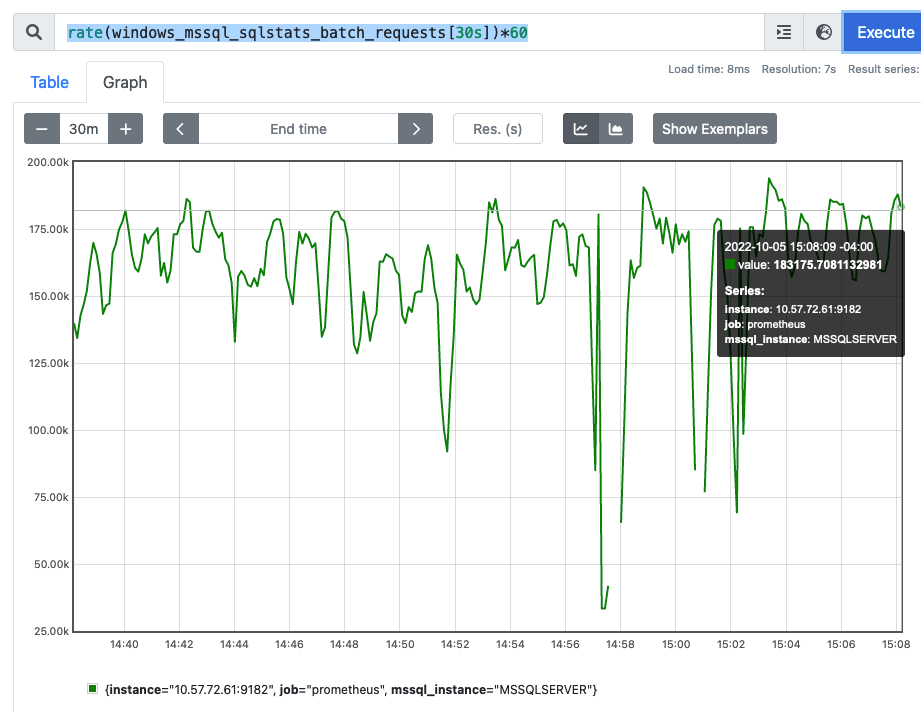
In each case we run the example with a 64MB allocation so that we can see the usage from standard linux tools.
We do something like this
gary@linux:~/git/unixfun$ ./malloc_and_write 65536
Allocating 65536 KB
Allocating 67108864 bytes
The address of your memory is 0x7fa2829ff010
Hit <return> to exit